The goal here is very simple: given a del.icio.us page with the url format http://del.icio.us/tag/mytag, where mytag is the tag I'm interested in, output a page containing a list where mytag is on the first line, and where all the tags related to mytag follow, one per line. We will use this list in Part 2 to construct a visualization of the relationships among these tags. A schematic of the preprocessor follows:
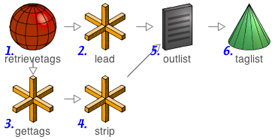
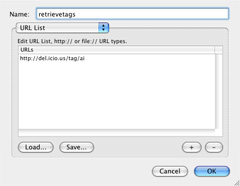
1. retrievetags: We first need to retrieve the original page. For the purposes of this tutorial we will use ai as the central tag - change this to any tag that you're interested in:
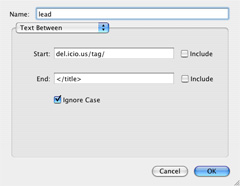
2. lead: We need to get the first line for our file (ai in our example). By looking at the source code for the page, we find that ai is contained in the HTML <title> section. We therefore extract it from there:
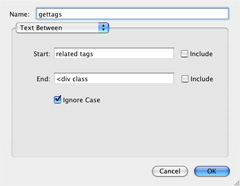
3. gettags: Now, we need to get the tags that are related to ai. By looking at the source code for the page, we find that the del.icio.us related tags section is contained between "related tags" and "<div class", so we extract it as below:
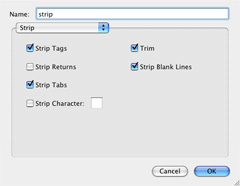
4. strip: Next, we get rid of all the HTML junk that accompanied our list of related tags:
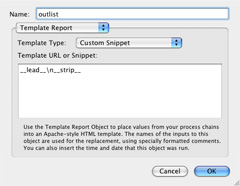
5. outlist: Having done that, we combine the result from 2. with the result from 4. into a single list. The custom snippet below means "write out the result of lead, then write out a carriage return, then write out the result of strip":
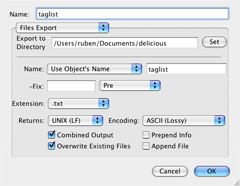
6. taglist: Finally, we take our list and write it out to a file called taglist.txt. Note that you will need to change the directory listed in "Export to Directory" to make it work with your system setup: